Ono čega mi uvek nedostaje, kad tražim stručne tekstove, su praktični primeri i korak-po-korak uputstva. Ovo drugo, bar za MySQL sam već pisao, baš na ovom blogu, pa hajde da dam malo i ovog prvog: Problemi iz prakse i njihovo rešavanje.
Kao što znate, MySQL omogućava horizontalno skaliranje putem ugrađenog mehanizma za replikaciju. Jedan server radi kao master, on prima upite koji menjaju datu, snima te izmene u replication log, i taj log deli svim slave serverima. Sam log je linearan, oblika sličnog dump-u – više manje tipa “INSERT INTO …. VALUES ….” . Slave ovo interpretira redno, što ponekad dovodi i do problema: Master je u stanju da izvrši mnogo paralelnih operacija, pod uslovom da su međusobno isključive, ali slave mora da ide redom. Kao rezultat toga, slave ponekad kasni za masterom. Mi, kao što smo već pisali o tome, za praćenje rada sistema koristimo mysql-mmm, koji čim to vreme kašnjenja pređe definisanu granicu, izbaci slave iz upotrebe sistema i da mu vremena da sustigne master. Dodatno, naravno, svi sistemi koji se oslanjaju na MySQL replikaciju imaju sistem koji sve vremenski kritične upite uvek salje na master.
Prva prednost ovoga je parcijalni ALTER TABLE. U ovakvom sistemu replikacije, moguće je pustiti ALTER TABLE na jednom po jednom slave-u, dok su izbačeni iz upotrebe. Sve dok se kolone dodaju na kraj, i imaju default vrednost, sistem će raditi bez problema. Konačno, jedan slave se proglasi za novi master, alter se pusti na masteru, i na celom sistemu je, kaskadno, pušten ALTER TABLE, bez downtime-a.
Sve ovo zvuči kao divan sistem, i većinu vremena radi sjajno, kao što je i nama, sve do jednog petka, kada je jedan server počeo da ide u replication lag. Ništa strašno, imamo ih više, rekosmo i odosmo na vikend. Kad smo se vratili, dočekalo nas je lepo iznenađenje: Server je kasnio 250,000 sekundi. Za ceo vikend vreme je prolazilo, master je radio, a ovaj slave kao da je stao. Jednostavno, replication lag je rastao sekund za sekund.
Trebalo nam je skoro ceo dan da nađemo šta se desilo. Analiza je trajala satima. Probali smo da vadimo najčešće upite iz binarnog loga, da ubijamo dodatne indexe na slave-u, da bi radilo brže, pratili rad diska…. ali sve je radilo normalno. Sve što nam je palo na pamet nije pomoglo. Na kraju je problem indentifikovao kolega Marko Uskoković iz Mainstrem-a. Marko, hvala još jednom, poziv na ručak na naš račun ti je i dalje otvoren!
Mehanizam koji je gore opisan deluje jednostavno: UPDATE TABLE … VALUES… mehanizam radi sjajno, sve dok su tabele iste. Ali, ispostavilo se da na jednoj tabeli, iako je struktura podataka ista, fali primarni index! Sad, InnoDB tabele uvek imaju primarni index, ali kada ga korisnik ne definiše engine to uradi sam. Kao rezultat, umesto da UPDATE radi preko primarnog index-a, on je morao da radi full table scan. Rezultat, na tabeli od nekoliko desetina miliona redova, je bilo ovo usporenje. Kada smo, direktno na slave-u uradili samo još jedan ALTER TABLE i vratili primarni index da bude isti kao na masteru, sve je poletelo. Uostalom, evo i slike:
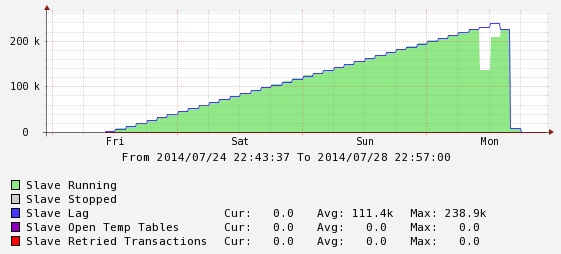
Evo, malo praktičnog iskustva. Trik za ALTER će, nadam se, svima biti od koristi, a ovaj praktični primer iz replikacije će vam, možda, jednog dana uštedeti sate i sate muke i nerviranja.




>Ali, ispostavilo se da na jednoj tabeli, iako je struktura podataka ista, fali primarni index!
Kako se to desilo?
Nemamo 100% potvrdu kako se desilo, mada je radna teorija da je problem nastao kada smo imali jedan hardverski problem sa tom masinom. Naime, tada je masina bila van upotrebe par dana, pa je morala da bude vracena iz bekapa – kada je, po nekoj nasoj proceni doslo do greske u importu strukture indexa.